
Ever since OpenAI’s ChatGPT became available for use at the end of the previous year, artificial intelligence turned a lot of heads in the IT industry. As time goes by, AI is gaining more and more momentum… Tech giants such as Google, Microsoft, IBM are using and testing it for their various purposes. Although everyone was delighted with the possibilities offered by this new technology initially, reality paints a different picture, one with problems, flaws and scandals…

Meta uses Facebook data to train its AI model!
Meta has published a new document, titled “Generative AI Data Subject Rights,” which offers users control over how their personal data is being used in their generative AI model. However, as is the case, important details are written in fine print. It is worth noting that this form does not give unlimited control over personal data, and instead, refers exclusively to third-party data that Meta could use to improve its AI.
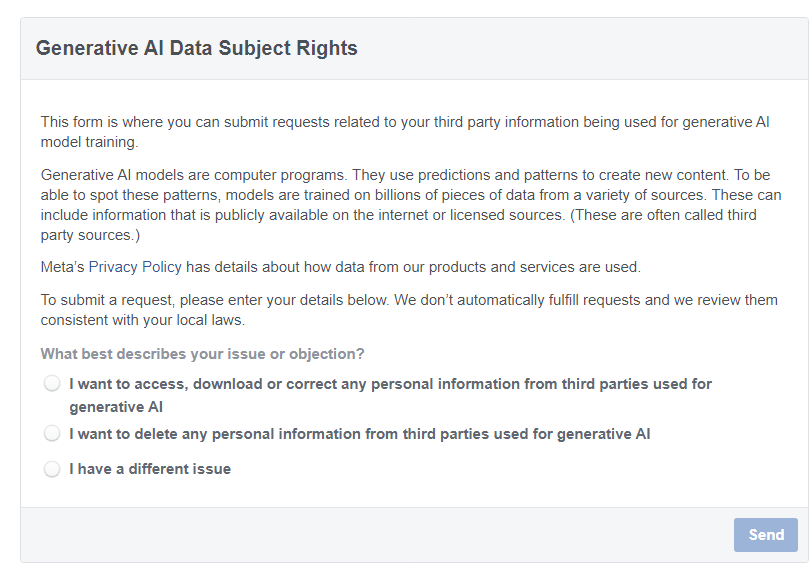
The Company allows its users to access, modify or delete personal data that has been included in various third-party data sources. This data is used by the company to train its advanced artificial intelligence languages.
What is the third party data?
Third-party data is the data that is publicly published on the Internet or data from licensed sources. This data is used to train generative AI models. For example, Facebook posts can contain personal data, which the company uses to train generative AI models…
What is the difference between generative and general artificial intelligence?
How can I learn about how Meta uses data for generative AI models?
The company did not inform its users that it was using data for its generative AI models, Instead, the company silently updated the information in Facebook’s privacy center. These are the steps that lead you to the detailed information about using data for generative AI models
- Click on your profile icon in the upper right corner of Facebook.
- Click on “Settings and Privacy”, then “Privacy Center”
- Click on “Other rules and articles”.
- Click on “How Meta Uses Data for Generative Models with Artificial Intelligence (AI)”
It is important to note that Meta’s new language model – Llama 2 is not trained on user data from Meta platforms and does not use user data from Meta platforms, including Facebook.
What is Llama 2?
LLama 2 is the second generation of Meta’s open source large language AI model. The model represents a family of large language models (LLMs) developed by Meta’s AI department, spanning a parameter spectrum spanning from 7 billion to 70 billion. According to Meta AI, Llama 2 is well-tuned for dialogues and has shown superior performance in various benchmarks compared to open source conversational models. Based on Meta’s human-conducted usability and security evaluations, Llama 2 is considered a potentially suitable alternative to closed-source models. Namely, Llama 2’s model training database is a collection of publicly available sources, excluding any data derived from Meta’s own products or services.









